Categories
Posts in this category
- The Fun of Running a Public Web Service, and Session Storage
- CPAN Pull Request Challenge: A call to the CPAN authors
- You Write Your Own Bio
- Icinga2, the Monitoring System with the API from Hell
- Progress in Icinga2 Land
- Iron Man Challenge - Am I a Stone Man?
- Correctness in Computer Programs and Mathematical Proofs
- Why Design By Contract Does Not Replace a Test Suite
- Doubt and Confidence
- Fun and No-Fun with SVG
- Goodby Iron Man
- Harry Potter and the Methods of Rationality
- Introducing my new project: Quelology organizes books
- iPod nano 5g on linux -- works!
- Keep it stupid, stupid!
- My Diploma Thesis: Spin Transport in Mesoscopic Systems
- Why is my /tmp/ directory suddenly only 1MB big?
Wed, 21 Dec 2016
Progress in Icinga2 Land
Permanent link
Last month I blogged about my negative experiences with the Icinga2 API. Since then, stuff has happened in Icinga2 land, including a very productive and friendly meeting with the Icinga2 product manager and two of the core developers.
My first issue was that objects created through the API sometimes don't show up
in the web interface. We learned that this can be avoided by explicitly specifying the zone attribute, and that Icinga 2.6 doesn't require this anymore.
The second issue, CREATE + UPDATE != CREATE isn't easy to fix in Icinga2.
Apply rules can contain basically arbitrary code, and tracking which ones to run,
possibly run in reverse etc. for an update is not easy, and while the Icinga2 developers
want to fix this eventually, the fix isn't yet in sight. The Icinga
Director has a
workaround, but it involves restarting the Icinga daemon for each change or
batch of changes, an operational characteristic we'd like to avoid.
The inability to write templates through the API stems from the same
underlying problem, so we won't see write support for templates soon.
The API quirks will likely remain. With support from the Icinga2 developers, I was able to get selection by element of an array variable working, though the process did involve finding at least one more bug in Icinga. The developers are working on that one, though :-).
Even though my bug report requesting more documentation has been closed, the Netways folks have improved the documentation thoroughly, and there are plans for even more improvements, for example making it easier to find the relevant docs by more cross-linking.
All in all, there is a definitive upwards trend in Icinga2's quality, and in my perception of it. I'd like to thank the Icinga2 folks at Netways for their work, and for taking the time to talk to a very vocal critic.
Tue, 08 Nov 2016
Icinga2, the Monitoring System with the API from Hell
Permanent link
Update 2016-12: We've met the Icinga2 developers, and talked through some of the issues. While not all could be resolved, the outlook seems much more positive after this. Please see my update for more information on the status quo.
At my employer, we have a project to switch some monitoring infrastructure from Nagios to Icinga2. As part of this project, we also change the way the store monitoring configuration. Instead of the previous assortment of manually maintained and generated config files, all monitoring configuration should now come from the CMDB, and changes are propagated to the monitoring through the Icinga2 REST API.
Well, that was the plan. And as you know, no plan survives contact with the enemy.
Call Me, Maybe?
Update 2016-12: This bug has been fixed in Version 2.6
We created our synchronization to Icinga2, and used in our staging environment for a while. And soon got some reports that it wasn't working. Some hosts had monitoring configuration in our CMDB, but Icinga's web interface wouldn't show them. Normally, the web interface immediately shows changes to objects you're viewing, but in this case, not even a reload showed them.
So, we reported that as a bug to the team that operates our Icinga instances, but by the time they got to look at it, the web interface did show the missing hosts.
For a time, we tried to dismiss it as an unfortunate timing accident, but in later testing, it showed up again and again. The logs clearly showed that creating the host objects through the REST API produce a status code of 200, and a subsequent GET listed the object. Just the web interface (which happens to be the primary interface for our users) stubbornly refused to show them, until somebody restarted Icinga.
Turns out, it's a known bug.
I know, distributed systems are hard. Maybe talk to Kyle aka Aphyr some day?
CREATE + UPDATE != CREATE
If you create an object through the Icinga API, and then update it to a different state, you get a different result than if you created it like that in the first place. Or in other words, the update operation is incomplete. Or to put it plainly, you cannot rely on it.
Which means you cannot rely on updates. You have to delete the resource and recreate it. Unfortunately, that implies you lose history, and downtimes scheduled for the host or service.
API Quirks
Desiging APIs is hard. I guess that's why the Icinga2 REST API has some quirks. For example, if a PUT request fails, sometimes the response isn't JSON, but plain text. If the error response is indeed JSON, it duplicates the HTTP status code, but as a float. No real harm, but really, WAT?
The next is probably debatable, but we use Python, specifically the
requests library, to talk to
Icinga. And requests insists on URL-encoding a space as a + instead of
%20, and Icinga insists on not decoding a + as a space. You can probably
dig up RFCs to support both points of view, so I won't assign any blame. It's
just annoying, OK?
In the same category of annoying, but not a show-stopper, is the fact that the
API distinguishes between singular and plural. You can filter for a single
host with host=thename, but if you filter by multiple hosts, it's
hosts=name1&host2=name2. I understand the desire to support cool, human-like
names, but it forces the user to maintain a list of both singular and plural
names of each API object they work with. And not every plural can be built by
appending an s to the singular. (Oh, and in case you were wondering, you
can't always use the plural either. For example when referring to an attribute
of an object, you need to use the singular).
Another puzzling fact is that when the API returns a list of services, the response might look like this:
{
"results": [
{
"attrs": {
"check_command": "ping4",
"name": "ping4"
},
"joins": {},
"meta": {},
"name": "example.localdomain!ping4",
"type": "Service"
},
]
}
Notice how the "name" and attrs["name"] attribute are different?
A service is always attached to the host, so the "name" attribute seems to be
the fully qualified name in the format <hostname>!<servicename>, and
attrs["name"] is just service name.
So, where can I use which? What's the philosophy behind having "name" twice, but with different meaning? Sadly, the docs are quiet about it. I remain unenlightened.
State Your Case!
Behind the scene, Icinga stores its configuration in files that are named
after the object name. So when your run Icinga on a case sensitive file
system, you can have both a service example.com!ssh and example.com!SSH at
the same time. As a programmer, I'm used to case sensitivity, and don't have
an issue with it.
What I have an issue with is when parts of the system are case sensitive, and
others aren't. Like the match() function that the API docs like to use. Is
there a way to make it case sensitive? I don't know. Which brings me to my
next point.
Documentation (or the Lack Thereof)
I wasn't able to find actual documentation for the match()
function. Possibly because there is
none. Who knows?
Selection Is Hard
Update 2016.12: The in operator works after all, if
you get it right. Using the script debugger in combination with an API request with filter=debugger is a neat way to debug such issues.
For our use case, we have some tags in the our CMDB, and a host can have zero, one or more tags. And we want to provide the user with the ability to create a downtime for all hosts that have tag.
Sounds simple, eh? The API supports creating a downtime for the result of an arbitrary filter. But that pre-supposes that you actually can create an appropriate filter. I have my doubts. In several hours of experimenting, I haven't found a reliable way to filter by membership of array variables.
Maybe I'm just too dumb, or maybe the documentation is lacking. No, not maybe.
The documentation is lacking. I made a point about the match() function
earlier. Are there more functions like match()? Are there more operators
than the ==, in, &&, || and ! that the examples use?
Templates
We want to have some standards for monitoring certain types of hosts. For example Debian and RHEL machines have slightly different defaults and probes.
That's where templates comes in. You define a template for each case, and simply assign this template to the host.
By now, you should have realized that every "simply" comes with a "but". But it doesn't work.
That's right. Icinga has templates, but you can't create or update them through the API. When we wanted to implement templating support, API support for templates was on the roadmap for the next Icinga2 release, so we waited. And got read-only support.
Which means we had to reimplement templating outside of Icinga, with all the scaling problems that come with it. If you update a template that's emulated outside of Icinga, you need to update each instance, of which there can be many. Aside from this unfortunate scaling issue, it makes a correct implementation much harder. What do you do if the first 50 hosts updated correctly, and the 51st didn't? You can try to undo the previous changes, but that could also fail. Tough luck.
Dealing with Bug Reports
As the result of my negative experiences, I've submitted two bug reports. Both have been rejected the next morning. Let's look into it.
In No API documentation for match()
I complained about the lack of discoverable documentation for the match()
function. The rejection pointed to this, which is half a line:
match(pattern, text) Returns true if the wildcard pattern matches the text, false otherwise.
What is a "wildcard pattern"? What happens if the second argument isn't a string, but an array or a dictionary? What about the case sensitivity question? Not answered.
Also, the lack of discoverability hasn't been addressed. The situation could easily be improved by linking to this section from the API docs.
So, somebody's incentive seems to be the number of closed or rejected issues, not making Icinga better usable.
To Be Or Not To Be
After experiencing the glitches described above, I feel an intense dislike whenever I have to work with the Icinga API. And after we discovered the consistency problem, my dislike spread to all of Icinga.
Not all of it was Icinga's fault. We had some stability issues with our own software and integration (for example using HTTP keep-alive for talking to a cluster behind a load balancer turned out to be a bad idea). Having both our own instability and the weirdness and bugs from Icinga made hard and work intensive to isolate the bugs. It was much less straight forward than the listing of issues in this rant might suggest.
While I've worked with Icinga for a while now, from your perspective, the sample size is still one. Giving advice is hard in that situation. Maybe the takeaway is that, should you consider to use Icinga, you would do well to evaluate extra carefully whether it can actually do what you need. And if using it is worth the pain.
Sat, 17 Sep 2016
You Write Your Own Bio
Permanent link
I love how children ask the hard questions. My daughter of 2.5 years tend to ask people out of the blue: "who are you?". Most answer with their names, and possibly with their relation to my daughter.
The nagging philosopher's voice in my head quietly comments, "OK, that's your name, but who are you?" And for that matter, who am I? My name is part of my identity, but there's more to me than my name. I hope :-).
Identity is hard to pin down, and shifts in time. Being a father, a husband and a part of a family is a big part of my identity. So is my work, software engineering and architecture. My personality traits, like being an introvert, and hopefully a kind person, are important too. As are the things that I do in my spare time. Like writing a book.
Speaking of books, please join me on a tangent.
You've read a technical book, and liked it. And the book case contained a blurb about the author: "Mr X is a successful software engineer and has worked for X, Y and Z. He has written several books on programming topics.". Plus a few sentences about his origins, family and hobbies, maybe.
Who writes these blurbs?
As a kid, I thought that the publisher hired journalists who did research on the author, to come up with a short bio that is both flattering and accurate.
Maybe the really big publishers do that. But mostly, the publishers just ask the author to provide a bio themselves.
I've written several articles in for technical print magazines, and that is exactly what happened. It's no secret either; it's right in the submission guidelines.
For my own book, which is self-published in digital form (and a print version being worked on by a small, independent publisher), I wrote my own bio, which was weird, because I had to talk about myself in the third person. And because I had to emphasize my strengths, which I'm typically not comfortable with.
You see where this is going, don't you?
The blurb, short bio, however you call it, is meant to shine a bit of light on the author's identity. This is to make the author more relatable, but also to serve as an endorsement. Which means that, depending of the topic of the publication it is attached to, it shines light on different parts of the identity. In the context of a book on software deployments, nobody cares that I kinda like cooking, but not enough to become really good at it.
So, should I call myself a successful software engineer, in the three-sentence autobiography? It sounds good, doesn't it? Am I comfortable with that description? I've had my share of successes in my professional career, and also some failures. If somebody else calls me successful, I take it as a compliment. If I put that moniker up myself, I cringe a bit. Should I? If others call me successful, it might just be my imposter syndrome kicking in.
But those adjectives are a small matter in comparison to other matters. Obviously, I write. Rambling stuff like what you're reading now. Articles. Blog posts. A book. Now, do I call myself a writer? Or an author? Do I want my gainful employment to become part of my identity?
There are no rules to do decide that. It's a choice. It's my choice.
And likely, it's a significant choice. If I consider myself a writer, the next project I'll be taking on is more likely to be another article, or a even book. If I consider myself a programmer, it's likely to be a small tool or a web app. I could decide I am an or even "the" maintainer of some Open Source projects I'm involved in. I can decide that I want to be something that I'm not yet, and make it happen.
I don't know what exactly I'll decide, but I love that I have a choice.
I'm writing a book on automating deployments. If this topic interests you, please sign up for the Automating Deployments newsletter. It will keep you informed about automating and continuous deployments. It also helps me to gauge interest in this project, and your feedback can shape the course it takes.
Thu, 01 Jan 2015
CPAN Pull Request Challenge: A call to the CPAN authors
Permanent link
The 2015 CPAN Pull Request Challenge is ramping up, and so far nearly two hundred volunteers have signed up, pledging to make one pull request for a CPAN distribution for each month of the year.
So here's a call to the all the CPAN authors: please be supportive, and if you
don't like for your CPAN distributions to be part of the challenge, please
send an email to neil at bowers dot com, stating your PAUSE ID and the fact
that you want to be excluded.
How to be supportive? The first step is to act on pull requests. If you don't have time for a review, please say so; getting some response, even if it's "it'll be some time 'till I get around to reviewing this" is much better than none.
The volunteers have varied backgrounds; some are seasoned veterans, others are beginners who will make their first contribution to Open Source. So please be patient and encouraging.
If you have specific requirements for contributions, add a file called CONTRIBUTING or CONTRIBUTING.md to your github repositories where you state those requirements.
And of course, be civil. But that goes without saying, right? :-)
(And to those CPAN authors who haven't done it yet: put your distributions on github, so that you're not left out of the fun!
Happy New Year everybody, and have a great deal of fun!
Sat, 15 Feb 2014
The Fun of Running a Public Web Service, and Session Storage
Permanent link
One of my websites, Sudokugarden, recently surged in traffic, from about 30k visitors per month to more than 100k visitors per month. Here's the tale of what that meant for the server side.
As a bit of background, I built the website in 2007, when I knew a lot less about the web and programming. It runs on a host that I share with a few friends; I don't have root access on that machine, though when the admin is available, I can generally ask him to install stuff for me.
Most parts of the websites are built as static HTML files, with Server Side Includes. Parts of those SSIs are Perl CGI scripts. The most popular part though, which allows you to solve Sudoku in the browser and keeps hiscores, is written as a collection of Perl scripts, backed by a mysql database.
When at peak times the site had more than 10k visitors a day, lots of
visitors would get a nasty mysql: Cannot connect: Too many open
connections error. The admin wasn't available for bumping the
connection limit, so I looked for other solutions.
My first action was to check the logs for spammers and crawlers that might hammered the page, and I found and banned some; but the bulk of the traffic looked completely legitimate, and the problem persisted.
Looking at the seven year old code, I realized that most pages didn't actually need a database connection, if only I could remove the session storage from the database. And, in fact, I could. I used CGI::Session, which has pluggable backend. Switching to a file-based session backend was just a matter of changing the connection string and adding a directory for session storage. Luckily the code was clean enough that this only affected a single subroutine. Everything was fine.
For a while.
Then, about a month later, the host ran out of free disk space. Since it is used for other stuff too (like email, and web hosting for other users) it took me a while to make the connection to the file-based session storage. What happened was 3 million session files on a ext3 file system with a block size of 4 kilobyte. A session is only about 400 byte, but since a file uses up a multiple of the block size, the session storage amounted to 12 gigabyte of used-up disk space, which was all that was left on that machine.
Deleting those sessions turned out to be a problem; I could only log in as
my own user, which doesn't have write access to the session files (which are
owned by www-data, the Apache user). The solution was to upload a
CGI script that deleted the session, but of course that wasn't possible at
first, because the disk was full. In the end I had to delete several gigabyte
of data from my home directory before I could upload anything again.
(Processes running as root were still writing to reserved-to-root portions of
the file system, which is why I had to delete so much data before I was able
to write again).
Even when I was able to upload the deletion script, it took quite some time to actually delete the session files; mostly because the directory was too large, and deleting files on ext3 is slow. When the files were gone, the empty session directory still used up 200MB of disk space, because the directory index doesn't shrink on file deletion.
Clearly a better solution to session storage was needed. But first I investigated where all those sessions came from, and banned a few spamming IPs. I also changed the code to only create sessions when somebody logs in, not give every visitor a session from the start.
My next attempt was to write the sessions to an SQLite database. It uses about 400 bytes per session (plus a fixed overhead for the db file itself), so it uses only a tenth of storage space that the file-based storage used. The SQLite database has no connection limit, though the old-ish version that was installed on the server doesn't seem to have very fine-grained locking either; within a few days I could errors that the session database was locked.
So I added another layer of workaround: creating a separate session database per leading IP octet. So now there are up to 255 separate session database (plus a 256th for all IPv6 addresses; a decision that will have to be revised when IPv6 usage rises). After a few days of operation, it seems that this setup works well enough. But suspicious as I am, I'll continue monitoring both disk usage and errors from Apache.
So, what happens if this solution fails to work out? I can see basically two approaches: move the site to a server that's fully under my control, and use redis or memcached for session storage; or implement sessions with signed cookies that are stored purely on the client side.
Mon, 31 Dec 2012
iPod nano 5g on linux -- works!
Permanent link
For Christmas I got an iPod nano (5th generation). Since I use only Linux on my home computers, I searched the Internet for how well it is supported by Linux-based tools. The results looked bleak, but they were mostly from 2009.
Now (December 2012) on my Debian/Wheezy system, it just worked.
The iPod nano 5g presents itself as an ordinary USB storage device, which you can mount without problems. However simply copying files on it won't make the iPod show those files in the play lists, because there is some meta data stored on the device that must be updated too.
There are several user-space programs that allow you to import and export music from and to the iPod, and update those meta data files as necessary. The first one I tried, gtkpod 2.1.2, worked fine.
Other user-space programs reputed to work with the iPod are rhythmbox and amarok (which both not only organize but also play music).
Although I don't think anything really depends on some particular versions here (except that you need a new enough version of gtkpod), here is what I used:
- Architecture: amd64
- Linux: 3.2.0-4-amd64 #1 SMP Debian 3.2.35-2
- Userland: Debian GNU/Linux "Wheezy" (currently "testing")
- gtkpod: 2.1.2-1
Thu, 23 Aug 2012
Correctness in Computer Programs and Mathematical Proofs
Permanent link
While reading On Proof and Progress in Mathematics by Fields Medal winner Bill Thurston (recently deceased I was sorry to hear), I came across this gem:
The standard of correctness and completeness necessary to get a computer program to work at all is a couple of orders of magnitude higher than the mathematical community’s standard of valid proofs. Nonetheless, large computer programs, even when they have been very carefully written and very carefully tested, always seem to have bugs.
I noticed that mathematicians are often sloppy about the scope of their symbols. Sometimes they use the same symbol for two different meanings, and you have to guess from context which on is meant.
This kind of sloppiness generally doesn't have an impact on the validity of the ideas that are communicated, as long as it's still understandable to the reader.
I guess on reason is that most mathematical publications still stick to one-letter symbol names, and there aren't that many letters in the alphabets that are generally accepted for usage (Latin, Greek, a few letters from Hebrew). And in the programming world we snort derisively at FORTRAN 77 that limited variable names to a length of 6 characters.
Sun, 26 Jun 2011
Introducing my new project: Quelology organizes books
Permanent link
For about half a year I've been working on a website called quelology, which collects book series and translations.
It is intended to answer questions of the form: I've now read "Harry Potter and the Order of the Phoenix", which is the next book in that series? or What's the name of the French translation of that book?
The website and data mining behind it are written in Perl, and it is based on book meta data by isfdb, amazon and worldcat.
I'm working on importing data from more sources, next up will be the Swedish National Library.
After completing the data mining stage, I'll add an interfaces that allows the visitor to edit the book, series and translations data, so that users can extend the data body.
Tue, 14 Jun 2011
Why is my /tmp/ directory suddenly only 1MB big?
Permanent link
Today I got a really weird error on my Debian "Squeeze" Linux box --
a processes tried to write a temp file, and it complained that there was
No space left on device.
The weird thing is, just yesterday my root parition was full, and I had made about 7GB free space in it.
I checked, there was still plenty of room today. But behold:
$ df -h /tmp/ Filesystem Size Used Avail Use% Mounted on overflow 1.0M 632K 392K 62% /tmp
So, suddenly my /tmp/ directory was a ram disc with just 1MB of space. And
it didn't show up in /etc/fstab, so I had no idea what cause
it.
After googling a bit around, I found the likely reason: as a protection against low disc space, some daemon automatically "shadows" the current /tmp/ dir with a ram disc if the the root partition runs out of disc space. Sadly there's no automatic reversion of that process once enough disc space is free again.
To remove the mount, you can say (as root)
umount -l /tmp/
And to permanently disable this feature, use
echo 'MINTMPKB=0' > /etc/default/mountoverflowtmp
Mon, 22 Nov 2010
Harry Potter and the Methods of Rationality
Permanent link
What if Harry Potter had been raised by a loving stepmother? What if his stepfather was a scientist? What happens when somebody tries to analyze magic with scientific methods? What happens if an eleven year old boy is too smart for his own good?
A piece of fan fiction, Harry Potter and the Methods of Rationality by "Less Wrong" answers those questions - and makes quite a good read. If you are into fantasy books and science, you might really love it. I did.
But be warned: only read this if you've read all seven Harry Potter books by J.K.Rowling, because the fan fiction piece contains lots of spoilers.
So far 60 chapters for varying length have been published, and just a few more to be written before the first year ends. I look forward to the final chapters.
Tue, 08 Dec 2009
Keep it stupid, stupid!
Permanent link
How hard is it to build a good search engine? Very hard. So far I thought that only one company has managed to build a search engine that's not only decent, but good.
Sadly, they seem to have overdone it. Today I searched for tagged dfa. I was looking for a technique used in regex engines. On the front page three out of ten results actually dealt with the subjects, the other uses of dfa meant dog friendly area, department of foreign affairs or other unrelated things.
That's neither bad nor unexpected. But I wanted more specific results, so I decided against using the abbreviation, and searched for the full form: tagged deterministic finite automaton. You'd think that would give better results, no?
No. It gave worse. On the first result page only one of the hits actually dealt with the DFAs I was looking for. Actually the first hit contained none of my search terms. None. It just contained a phrase, which is also sometimes abbreviated dfa.
WTF? Google seemed to have internally converted my query into an ambiguous, abbreviated form, and then used that to find matches, without filtering. So it attempted to be very smart, and came out very stupid.
I doubt that any Google engineer is ever going to read this rant. But if one is: Please, Google, keep it stupid, stupid.
I'm fine with getting automatic suggestions on how to improve my search query; but please don't automatically "improve" it for me. I want to find what I search for. I'm not interested in dog friendly areas.
Sat, 05 Dec 2009
Doubt and Confidence
Permanent link
<meta>From my useless musings series.</meta>
As a programmer you have to have confidence in your skills, to some extent, and at the same time you have to constantly doubt them. Weird, eh?
Confidence
You need some level of confidence to do anything efficiently. Planning ahead requires confidence that you can achieve the steps on your way.
As a programmer you also need some confidence with the language, libraries and other tools you're using.
If you program for money, you also have to assess what kind of programs you can write, and where you might have problems.
Doubt
In the process of programming you make a lot of assumptions, some of the explicit, some of them implicit. If you want to write a good program, it's essential that you are aware of as many assumptions as possible.
When you find a bug in your program, you have to challenge previous assumptions, and that's where doubt comes in. You not only suspect, but you know that at least one of the assumptions was false (or maybe just a bit too specific), and you know that you did something wrong.
Sometimes programmers make really stupid mistakes which are rather tricky to track down. That's when you have to question your own sanity.
One example (that luckily doesn't happen all that often to me) is when I edit my program, and nothing seems to change. Nothing at all. Depending on the setup it might be some cache, but something it is even more devious - for example I didn't notice that the console where I edit and the console where I test are on different hosts - and thus the edits actually have no effect at all.
After having done such a thing once or twice I adopted the habit of just
adding a die('BOOM'); instruction to my code, to verify that
the part I'm looking at is actually run.
These are moments when I question my own sanity, thinking "how could I have possibly done such a stupid thing?". Doubt.
The same phenomena applies when doing scientific research: since you usually do things that nobody has done before (or at nobody has published about it yet), you can't know the results beforehand -- if you could, your research would be rather boring. So you have no external reference for verification, only your intuition and discussion with peers.
Sat, 10 Oct 2009
Fun and No-Fun with SVG
Permanent link
Lately I've been playing a lot of with SVG, and all in all I greatly enjoyed it. I wrote some Perl 6 programs that generate graphical output, and being a new programming language it doesn't have many bindings to graphic libraries. Simply emitting a text description of a graphic and then viewing it in the browser is a nice and simple way out.
I also enjoy getting visual feedback from my programs. I'd even more enjoy it if the feedback was more consistent.
I generally test my svg images with three different viewers: Firefox 3.0.6-3, inkscape (or inkview) 0.46-2.lenny2 and Opera 10.00.4585.gcc4.qt3. Often they produce two or more different renderings of the same SVG file.
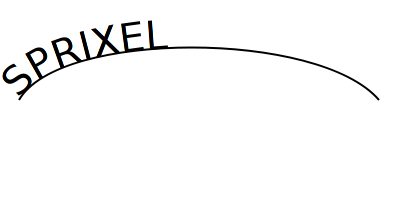
Consider this seemingly simple SVG file:
<svg width="400" height="250" xmlns="http://www.w3.org/2000/svg" xmlns:svg="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" style="background-color: white" > <defs> <path id="curve" d="M 20 100 C 60 30 320 30 380 100" style="fill:none; stroke:black; stroke-width: 2" /> </defs> <text font-size="40" textLength="390" > <use xlink:href="#curve" /> <textPath xlink:href="#curve">SPRIXEL</textPath> </text> </svg>
If your browser supports SVG, you can view it directly here.
{kind=link}
This SVG file first defines a path, and then references it twice: once a text is placed on the path, the second time it is simply referenced and given some styling information.
Rendered by Firefox:
Rendered by Inkview:

Rendered by Opera:
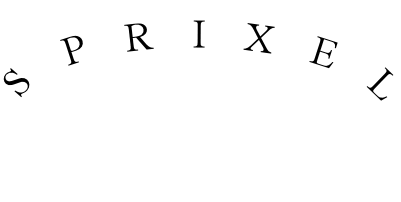
Three renderers, three outputs. Neither Firefox nor Inkview support the
textLength attribute, which is a real pity, because it's the only
way you can make a program emit SVG files where text is guaranteed not to
overlap.
If you scale text in Inkscape and then put it onto a path, the scaling is
lost. I found no way to reproduce opera's output with inkscape without
resorting to really evil trickery (like decomposing the text into paths, can
then cutting the letters apart and placing them manually). (Equally useful is
the dominant-baseline attribute, which Inkscape doesn't support
either).
The second difference is that only Firefox shows the shape of the path.
Firefox is correct here. The SVG specification clearly
states about the use attribute:
For user agents that support Styling with CSS, the conceptual deep cloning of the referenced element into a non-exposed DOM tree also copies any property values resulting from the CSS cascade [CSS2-CASCADE] on the referenced element and its contents. CSS2 selectors can be applied to the original (i.e., referenced) elements because they are part of the formal document structure. CSS2 selectors cannot be applied to the (conceptually) cloned DOM tree because its contents are not part of the formal document structure.
Sadly it seems to be a coincidence that Firefox works correctly here. If
the styling information is moved from the path to the
use element the curve is still displayed - even though it should
not be.
Using SVG feels like writing HTML and CSS for 15 year old browsers, which had their very own, idiosyncratic idea of how to render what, and what to support and what not.
Just like with HTML I have high hopes that the overall state will improve;
Indeed I've been told that Firefox 3.5 now supports the
textLength attribute. I'd also love to see wide-spread support
for SVG animations, which could replace some inaccessible flash
applications.
Tue, 04 Aug 2009
Goodby Iron Man
Permanent link
<update> (from 2009-08-23) It turned out that my disappearance on the ironman blog feed was due to a broken RSS feed. Matt S. Trout tried to inform me by blog comment, my blog marked it as spam and swallowed it.
So now we talked on IRC, clarified things, and I'm back in the game. </update>
So I accepted the Iron Man blogging challenge a few month ago. And last week I discovered that my blog was gone from their feed. For the second time. Without any notification.

Image: rusty iron man, by courtesy of artvixn, available under a create commons non-commerical by-attribution license.
The first time they had a good reason: the date tags in my RSS feed were goofed; still I'd thought it would be nice to at least notify me of such a removal. After some mails back and forth I was able to fix it; after the second removal without any notification I'm simply fed up and don't want to investigate any more energy into this.
Still I'll continue to follow the collected RSS feed, there are still many interesting blogs to be read there.
Tue, 23 Jun 2009
Iron Man Challenge - Am I a Stone Man?
Permanent link
Gabor asked what I'm missing from the Iron Man blogging challenge. Gabor focused on the contents of the blog posts, I'll talk about the challenge itself.
I'm missing the things announced on their website: a way to find out to which level you made it, a monthly selection of best blog posts, and all these other things that were designed to create some competition, and more fun.
Don't get me wrong, I like to read the blog of my fellow Perl programmers, and it motivates me to write more often myself. But that's not all that was promised to us.
One thing I'd like to add about the content, though: So far most of what I read was very good and informative, but it was all text. I know it's not easy to find nice on-topic programming pictures, and use.perl.org doesn't even allow the inclusion of pictures in posts, and I don't do it often myself, but having more picture or charts would be nice.